
9月18日,DeepSeek再次引发动荡。由DeepSeek团队共同完成、梁文锋担任通信作家的DeepSeek-R1筹论说文,登上了国外巨擘期刊《Nature》的封面。

本年1月,DeepSeek曾在arxiv公布了第一版预印本论文,相较而言,这次发布在《Nature》的版块补充了更多模子细节,减少了描写中的拟东谈主化证实。在补充材料中,DeepSeek提到了R1模子的稽查本钱仅29.4万好意思元,以及恢复了模子发布之初对于蒸馏OpenAI的质疑。
本年1月,有报谈提到,OpenAI斟酌东谈主员以为,DeepSeek可能使用了OpenAI模子的输出来稽查R1,这种花式不错在使用较少资源的情况下加快模子才智提高。
在论文的补充而已部分,DeepSeek恢复了对于DeepSeek-V3-Base稽查数据开首的问题。“DeepSeek-V3-Base的稽查数据仅来自普通网页和电子书,不包含任何合成数据。在预稽查冷却阶段,咱们莫得异常加入OpenAI生成的合成数据,此阶段使用的所少见据齐是通过网页持取的。”DeepSeek暗示。

不外,DeepSeek也证实,已不雅察到一些网页包含普遍OpenAI模子生成的谜底,这可能导致基础模子曲折受益于其他宽广模子的学问。此外,预稽查数据集包含普遍数学和编程斟酌骨子,标明DeepSeek-V3-Base已经战役到普遍有推理印迹的数据。这种浅薄的战役使模子概况生成较为合理的处分决策,强化学习不错从中识别并优化输出质料。DeepSeek暗示,已在预稽查中针对数据期侮进行了处理。
哥伦布市俄亥俄州立大学的AI斟酌员Huan Sun暗示,这一反驳"与咱们在职何出书物中看到的骨子相同具有劝服力"。Hugging Face的机器学习工程师、同期亦然论文审稿东谈主之一的Lewis Tunstall补充说,尽管他不可100%细目R1未基于OpenAI示例进行稽查,但其他施行室的复制尝试标明,DeepSeek的推理决策可能实足优秀而无须这么作念。"我以为现存把柄已十分明确地标明,仅使用纯强化学习即可取得极高性能。"他暗示。
DeepSeek也在补充而已部分提到DeepSeek-R1的稽查本钱。在DeepSeek-R1的斟酌过程中,团队使用 A100 GPU 完成了较小限度模子(30B参数)的施行,随后团队将稽查膨大至 660B参数的R1-Zero和R1模子。
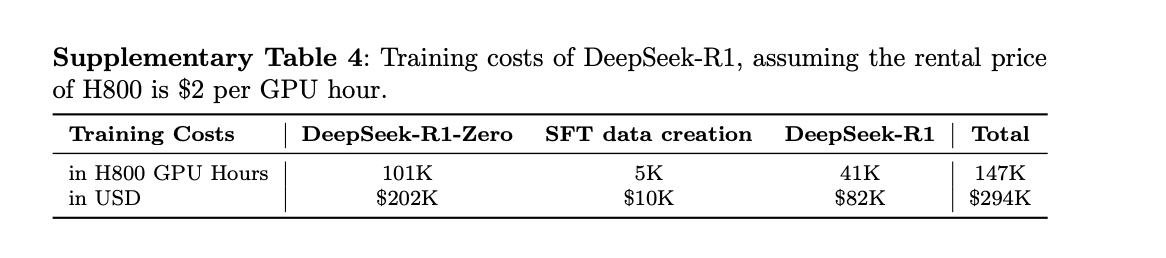
具体而言,DeepSeek-R1-Zero稽查使用了64×8张H800GPU,耗时约198小时。DeepSeek-R1稽查相同使用了64×8张H800 GPU,耗时约4天(约80小时)。此外,构建SFT数据集滥用了约5000小时的GPU运算。
DeepSeek暗示,假定H800的租出价钱为每小时2好意思元,DeepSeek-R1-Zero稽查本钱20.2万好意思元,SFT数据集创建破耗1万好意思元,DeepSeek-R1稽查本钱8.2万好意思元,这三项的总本钱为29.4万好意思元。折合成东谈主民币,这些本钱约200万元。
R1基于DeepSeek-V3模子稽查,不外,即便加上稽查V3模子所破耗的约600 万好意思元稽查本钱,总金额仍远低于竞争敌手的模子所破耗的数千万好意思元。
DeepSeek-R1已经成为了众人最受迎接的开源推理模子,Hugging Face下载量超1090万次。到现在为止,DeepSeek-R1亦然众人首个经过同业评审的主流谎话语模子。
Lewis Tunstall暗示,“这是一个相等受迎接的前例,若是莫得公开共享这依然由大部安分容的标准,就很难评估这些系统是否存在风险。”面前 AI 行业不乏刷榜的传说,基准测试可被操控,而经过孤立的同业评审昭彰也能排除疑虑。
具体到这次发布论文骨子,其题目是《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,主要公开了仅靠强化学习,就能激勉大模子推理才智的紧要斟酌效力。
、
以往的斟酌主要依赖普遍监督数据来提高模子性能。DeepSeek的开发团队则开辟了一种全新的念念路,即使无须监督微调(SFT)手脚冷初始,通过大限度强化学习也能显耀提高模子的推理才智。若是再加上极少的冷初始数据,效果会更好。
在强化学习中,模子正确解答数学问题时会取得高分奖励,答错则会受到刑事连累。因此模子学会了推理,冉冉处分问题并揭示这些风光,从而更有可能得出正确谜底。这使得 DeepSeek-R1 概况自我考据和自我反念念,在给出新问题的谜底之前稽查其性能,从而提高其在编程和斟酌生水平科学问题上的进展。
DeepSeek在模子稽查中,摄取了群组相对政策优化(GRPO)来裁减稽查本钱,贪图奖励机制决定着强化学习优化的标的,同期团队贪图了简便模板来结合基础模子,条目模子先给出推理过程,再提供最终谜底。
为了使更高效的小模子具备 DeepSeek-R1 那样的推理才智,开发团队还径直使用 DeepSeek-R1 整理的 80 万个样本对 Qwen 和 Llama 等开源模子进行了微调。斟酌终结标明,这种简便的蒸馏花式显耀增强了小模子的推理才智。
举报 第一财经告白合营,请点击这里此骨子为第一财经原创,文章权归第一财经统统。未经第一财经籍面授权,不得以任何形势加以使用,包括转载、摘编、复制或斥地镜像。第一财经保留根究侵权者法律连累的权力。如需取得授权请斟酌第一财经版权部:banquan@yicai.com 文章作家
刘晓洁

郑栩彤
斟酌阅读 DeepSeek-R1创始历史,梁文锋论文登上《当然》封面
DeepSeek-R1创始历史,梁文锋论文登上《当然》封面本次论文正面恢复了模子发布之初的蒸馏质疑。
247 5小时前 武汉大学斟酌生院恢复杨某媛论文知网下架:正在核实
武汉大学斟酌生院恢复杨某媛论文知网下架:正在核实该论文下载量曾达31万次以上,在文件开首为“武汉大学”的论文中高居第一。
279 09-10 10:17 AI周报 | DeepSeek斩获ACL 2025最好论文;库克称苹果计算“大幅”增多AI投资
AI周报 | DeepSeek斩获ACL 2025最好论文;库克称苹果计算“大幅”增多AI投资Anthropic迥殊OpenAI成首选;阶跃星辰开源基础大模子Step 3。
211 08-03 08:55 本钱上风将培植AI居品中的“王者”
本钱上风将培植AI居品中的“王者”AI居品本钱的终结不错从最优性价比参数采选、硬件组合、数据预处理和小样本学习、自动化器具的使用四个方面发力。跟着AI居品的冉冉交易化,本钱的紧要性将渐渐显知道来。
262 06-11 22:37 DeepSeekR1幻觉率最高裁减50%,用户喊话想要R2模子
DeepSeekR1幻觉率最高裁减50%,用户喊话想要R2模子陈说炫夸此前 R1模子幻觉率在21%把握开yun体育网。
302 05-29 21:34 一财最热 点击关闭